Private Link + ECR を試す
概要
従来は ECR からコンテナイメージを取得するために、IGW、NATGW を使用していたが、
Private Link の登場によりこれらが不要になった。
料金や、セキュリティの観点から Private Link 経由での方がメリットが多い。
料金について
Private Link
$ 0.014 * 720 = $ 10.08
$ 0.01 per 1GB processed
NAT GW
0.062 * 720 = $ 44.64(月額固定)
$ 0.062 per 1GB processed
検証環境
ECR
- hasegawa-privatelink
S3
- hasegawa-privatelink
VPC エンドポイントの作成
3つのエンドポイントを作成する。
- com.amazonaws.us-west-2.ecr.dkr
- com.amazonaws.us-west-2.s3
- com.amazonaws.us-west-2.logs
ECR へのエンドポイント

S3 へのエンドポイント

コンテナイメージの実態は S3 にある。
CWL へのエンドポイント

コンテナが CWL へ書き込む際に必要。
ECR エンドポイントの SG

動作確認
実際に Private Link 経由で ECR からイメージを引っ張って動作確認をする。
使用したイメージをこれ
hub.docker.com
イメージの URL は ECR のままで大丈夫。
number.dkr.ecr.us-west-2.amazonaws.com/hasegawa-privatelink:latest


確認

問題なく、イメージを引っ張って動作確認できた。
MySQL innodb_buffer_pool_instances を調整したら幸せになれました







ECS と distroless イメージの組み合わせは悲しい
最近見るプロジェクトが増えました。
ECS コンテナのヘルスチェックにいつもどおり何かを書く
CMD,curl,localhost
しかし、永遠に UNKNOWN になる。
使ってるイメージを持ってきてローカルで確認してみる。
$ luis@ubuntu ~ $ docker run --name test -it --rm --entrypoint "bash" docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"bash\": executable file not found in $PATH": unknown. $ luis@ubuntu ~ $ docker run --name test -it --rm --entrypoint "sh" docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknown. $ luis@ubuntu ~ $ docker run --name test -it --rm --entrypoint "curl" docker: Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"curl\": executable file not found in $PATH": unknown.
どうやって、Docker イメージを作ってるのか調べてみると jib とかいうのを使ってるらしい。
そこにベースのイメージを指定できるのだけど
jib {
from {
image = "gcr.io/distroless/java:11"
}
...
}
gcr.io/distroless/java:11 をベースイメージに作ってるらしい。
They do not contain package managers, shells or any other programs you would expect to find in a standard Linux distribution.
なるほど。
Stripe Checkout をローカルの Vue で動作確認する


コンテナで動かしてる MySQL で innodb_dedicated_server = 1 にしたらどんどん死んでいった話
ある日 InnoDB Cluster をコンテナ上で動かしてたがメモリを期待していた以上に消費していたので調べていた。
その時は innodb_dedicated_server を 1 にしてた。
innodb_dedicated_server
MySQL 8.0 から追加された変数で自動で innodb_buffer_pool_size とかを自動で決めてくれる便利もの。
dev.mysql.com
ソースを覗いてみる
buffer_pool_size が決まるところ
ha_Innodb.cc:3992 で innodb_dedicated_server が ON の場合の分岐が走り、
ha_innodb.cc:3999 でサーバーにあるメモリ量を取得して innodb_buffer_pool_size が決まる。
ha_innodb.cc の innodb_buffer_pool_size_init 部分 ↓
/** Initialize and normalize innodb_buffer_pool_size. */ static void innodb_buffer_pool_size_init() { #ifdef UNIV_DEBUG ulong srv_buf_pool_instances_org = srv_buf_pool_instances; #endif /* UNIV_DEBUG */ acquire_sysvar_source_service(); /* If innodb_dedicated_server == ON */ if (srv_dedicated_server && sysvar_source_svc != nullptr) { static const char *variable_name = "innodb_buffer_pool_size"; enum enum_variable_source source; if (!sysvar_source_svc->get( variable_name, static_cast<unsigned int>(strlen(variable_name)), &source)) { if (source == COMPILED) { double server_mem = get_sys_mem(); if (server_mem < 1.0) { ; } else if (server_mem <= 4.0) { srv_buf_pool_size = static_cast<ulint>(server_mem * 0.5 * GB); } else srv_buf_pool_size = static_cast<ulint>(server_mem * 0.75 * GB); } else { ib::warn(ER_IB_MSG_533) << "Option innodb_dedicated_server" " is ignored for" " innodb_buffer_pool_size because" " innodb_buffer_pool_size=" << srv_buf_pool_curr_size << " is specified explicitly."; } } } release_sysvar_source_service(); if (srv_buf_pool_size >= BUF_POOL_SIZE_THRESHOLD) { if (srv_buf_pool_instances == srv_buf_pool_instances_default) { #if defined(_WIN32) && !defined(_WIN64) /* Do not allocate too large of a buffer pool on Windows 32-bit systems, which can have trouble allocating larger single contiguous memory blocks. */ srv_buf_pool_instances = ut_min(static_cast<ulong>(MAX_BUFFER_POOLS), static_cast<ulong>(srv_buf_pool_size / (128 * 1024 * 1024))); #else /* defined(_WIN32) && !defined(_WIN64) */ /* Default to 8 instances when size > 1GB. */ srv_buf_pool_instances = 8; #endif /* defined(_WIN32) && !defined(_WIN64) */ } } else { /* If buffer pool is less than 1 GiB, assume fewer threads. Also use only one buffer pool instance. */ if (srv_buf_pool_instances != srv_buf_pool_instances_default && srv_buf_pool_instances != 1) { /* We can't distinguish whether the user has explicitly started mysqld with --innodb-buffer-pool-instances=0, (srv_buf_pool_instances_default is 0) or has not specified that option at all. Thus we have the limitation that if the user started with =0, we will not emit a warning here, but we should actually do so. */ ib::info(ER_IB_MSG_534) << "Adjusting innodb_buffer_pool_instances" " from " << srv_buf_pool_instances << " to 1" " since innodb_buffer_pool_size is less than " << BUF_POOL_SIZE_THRESHOLD / (1024 * 1024) << " MiB"; } srv_buf_pool_instances = 1; } #ifdef UNIV_DEBUG if (srv_buf_pool_debug && srv_buf_pool_instances_org != srv_buf_pool_instances_default) { srv_buf_pool_instances = srv_buf_pool_instances_org; }; #endif /* UNIV_DEBUG */ srv_buf_pool_chunk_unit = buf_pool_adjust_chunk_unit(srv_buf_pool_chunk_unit); srv_buf_pool_size = buf_pool_size_align(srv_buf_pool_size); ut_ad(srv_buf_pool_chunk_unit >= srv_buf_pool_chunk_unit_min); ut_ad(srv_buf_pool_chunk_unit <= srv_buf_pool_chunk_unit_max); ut_ad(srv_buf_pool_chunk_unit % srv_buf_pool_chunk_unit_blk_sz == 0); ut_ad(srv_buf_pool_chunk_unit % UNIV_PAGE_SIZE == 0); ut_ad(0 == srv_buf_pool_size % (srv_buf_pool_chunk_unit * srv_buf_pool_instances)); ut_ad(srv_buf_pool_chunk_unit * srv_buf_pool_instances <= srv_buf_pool_size); srv_buf_pool_curr_size = srv_buf_pool_size; }
メモリサイズを返しているところ
get_sys_mem() でサーバーに割り当てられたメモリ量を取得している。
ha_innodb.cc:297 ↓
static double get_mem_sysconf() { return (((double)sysconf(_SC_PHYS_PAGES)) * ((double)sysconf(_SC_PAGESIZE) / GB)); }
_SC_PHYS_PAGES
物理メモリのページ数
_SC_PAGESIZE
バイト単位でのページサイズ
MySQL はメモリの管理方式としてはページング方式を使っていて物理メモリのページ数と1ページ辺りのサイズをかけて返してるらしい。
_SC_PHYS_PAGES は物理マシンのページ数を返すのでコンテナ(プロセス)で動かす場合では不都合が起きる。
似たようなことを経験したことがあったからある程度予測はついていた。
blog.luispc.com
C 読めないし、MySQL Server はソースが膨大でコンパイルして開くまで30分かかった。
間違ってたら(補足があったら)教えてくれると助かります🙏
GTID で errant transaction に悩んだら
TL;DR
- flush slow logs のタイミングでバイナリログに書き込まれる
- それによって GTID がズレる = errant transaction
- このスクリプトを mackerel-agent で定期実行することで解決
事象
あるタイミングでスレーブの GTID が進んで errant gtid が起きる。
flush slow logs はバイナリログに書かれるよ
FLUSH PRIVILEGESやFLUSH TABLESはバイナリーログに書かれるのでgtid_executedに記録されるよ
バイナリログを調べる
general_log に書かれる server id はもちろんスレーブの。 バイナリログのは server id は、マスターの server id になる。
↓ こんなスクリプトで調べていった。
#!/bin/bash
logs=(000003 000004 000005 000006 000007 000008 000009 000010 000011 000012 000013 000014 000015)
for log in "${logs[@]}"
do
mysqlbinlog /var/lib/mysql/mysql-bin.${log} --result-file=/mnt/data/output_${log} -v
echo "${log}: $( cat /mnt/data/output_${log} | grep 'server id 101941095' |wc -l )"
done
これの出力結果はこんな感じになる ↓
000003: 3
000004: 3
000005: 3
000006: 3
000007: 3
000008: 3
000009: 3
000010: 5
000011: 3
000012: 3
000013: 3
000014: 3
000015: 3
server_id: 101941095 がバイナリログ上に出現した数が出力される。
3 は正常で、それ以上が怪しいやつ。
つまり、mysql-bin.000010 が怪しい。
mysql-bin.000010 を調べる
# at 418792896
#200216 3:12:01 server id 101941095 end_log_pos 418792944 CRC32 0xe049bbeb GTID [commit=yes]
SET @@SESSION.GTID_NEXT= 'ac8a2a1b-31d2-11ea-ad13-fa163eee324c:11'/*!*/;
# at 418792944
#200216 3:12:01 server id 101941095 end_log_pos 418793022 CRC32 0x1b3c4ada Query thread_id=3743 exec_time=0 error_code=0
SET TIMESTAMP=1581790321/*!*/;
SET @@session.sql_mode=1075838976/*!*/;
flush slow logs
/*!*/;
# at 418793022
# #200216 3:12:01 server id 101941095 end_log_pos 418793022 CRC32 0x1b3c4ada Query thread_id=3743 exec_time=0 error_code=0
# SET TIMESTAMP=1581790321/*!*/;
# SET @@session.sql_mode=1075838976/*!*/;
# flush slow logs
# /*!*/;
# # at 418793022
# //
SET TIMESTAMP=1581803224/*!*/;
BEGIN
/*!*/;
flush slow logs ... :thinking_face:
(寄り道)3 回出現する理由
気になる。
1回目
# at 4
#200215 14:22:31 server id 101941095 end_log_pos 120 CRC32 0x64963fc6 Start: binlog v 4, server v 5.6.44-log created 200215 14:22:31
BINLOG '
F4BHXg9nfxMGdAAAAHgAAAAAAAQANS42LjQ0LWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXAAEGggAAAAICAgCAAAACgoKGRkAAcY/
lmQ=
'/*!*/;
起動時。 これが何をしているのかは不明なので教えてください。
2回目
# at 121
#200215 14:22:31 server id 101941095 end_log_pos 471 CRC32 0x725344f8 Previous-GTIDs
# 54a349d8-311a-11ea-a861-fa163efc07d0:1-10,
# 7aab7d0a-32f1-11ea-b461-fa163e7976a1:1-10,
# 7ac09f23-32f1-11ea-b461-fa163ed61f9a:1-502880417,
# 864f8199-0b58-11ea-b22c-fa163eb7e9f7:1-892916580,
# ac8a2a1b-31d2-11ea-ad13-fa163eee324c:1-10,
# d46dd772-0b58-11ea-b22e-fa163ee8afa4:1-10,
# d7128fda-0b58-11ea-b22e-fa163e9f03bc:1-1778530447,
# fef8730c-45b7-11ea-aed0-fa163e09984a:1-10
GTID の仕様上で、過去に実行してきた GTID を全て知っている必要がある。
バイナリログの先頭には、↑ のように今まで実行した GTID を記録し、gtid_executed に保存される。
3回目
# at 1073741881
#200215 16:29:17 server id 101941095 end_log_pos 1073741928 CRC32 0xdecb3708 Rotate to mysql-bin.000003 pos: 4
DELIMITER ;
# End of log file
新しいバイナリログへのローテート時
原因
まさにこれだった。
FLUSH PRIVILEGESやFLUSH TABLESはバイナリーログに書かれるのでgtid_executedに記録されるよ
確認
flush slow logs を叩いてみる。
before

after

ac8a2a1b-31d2-11ea-ad13-fa163eee324c:1-14 → ac8a2a1b-31d2-11ea-ad13-fa163eee324c:1-15 になった。無事、errant transaction の完成です。
解決
flush slow logs をやめるのは流石にキツイのでスクリプトを回す。
Orchestrator を Mackerel と組み合わせて幸せを掴むスクリプト
なにしてるの
- errant transaction の検知
- errant transaction の修正
- can-replicate-from-gtid を叩く
errant transaction の検知
function check_errant {
for cluster in "${CLUSTERS[@]}"
do
replicas=( $( orchestrator -c which-replicas -i "${cluster}") )
for replica in "${replicas[@]}"
do
local result=$( orchestrator -c which-gtid-errant -i "${replica}" )
if [ -n "${result}" ]; then
inject_empty_transaction "${replica}"
fi
done
done
}レプリカが errant transaction を持っていた場合は、
inject_empty_transaction を実行する。
local result=$( orchestrator -c which-gtid-errant -i "${replica}" )
if [ -n "${result}" ]; then
inject_empty_transaction "${replica}"
fi
errant transaction の修正
function inject_empty_transaction {
local replica="${1}"
orchestrator -c gtid-errant-inject-empty -i "${replica}"
}なんで問答無用で inject empty transaction してるかというと、、、
次の記事に書く予定。
can-replicate-from-gtid を叩く
function can_replicate {
for cluster in "${CLUSTERS[@]}"
do
replicas=( $( orchestrator -c which-replicas -i "${cluster}") )
for replica_i in "${!replicas[@]}"
do
for other_i in "${!replicas[@]}"
do
if [ ${replica_i} -eq ${other_i} ]; then
continue
fi
source_replica="${replicas[${replica_i}]}"
destination="${replicas[${other_i}]}"
set +e
result=$( orchestrator -c can-replicate-from-gtid -i "${source_replica}" -d "${destination}" )
if [ $? -ne 0 ]; then
echo -e "${source_replica} to ${destination} cannot replicate\nError: ${result}\nCheck errant gtid http://<orchestrator ip>:3000/web/cluster/alias/prd-dbs07"
exit 2
fi
set -e
done
done
done
}マスターを除く全てのレプリカ同士でレプリケーションが貼れるかどうかを調べる。
Mackerel で使う
[plugin.checks.can_replicate_from_gtid] command = "bash /usr/local/bin/canreplicate.sh" notification_interval = 10 max_check_attempts = 3 check_interval = 3
max_check_attempts = 3 こうしてるのはタイミング悪いと can-replicate-from-gtid が失敗するから(register-candidate とタイミングが被ると良くないっぽい)
CentOS 8 で mysql-community-server 8.0.19 を入れる
dnf め...
mysql repo を入れる
# dnf install https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm -y
mysql-community-server を探す
# dnf list | grep mysql-community-server mysql-community-server-debug.x86_64 8.0.19-1.el8 mysql80-community mysql-community-server-debug-debuginfo.x86_64 8.0.19-1.el8 mysql80-community mysql-community-server-debuginfo.x86_64 8.0.19-1.el8 mysql80-community
あれ、、、?
mysql module を切る
# dnf -y module disable mysql
探す
# dnf list | grep mysql-community-server mysql-community-server.x86_64 8.0.19-1.el8 mysql80-community mysql-community-server-debug.x86_64 8.0.19-1.el8 mysql80-community mysql-community-server-debug-debuginfo.x86_64 8.0.19-1.el8 mysql80-community mysql-community-server-debuginfo.x86_64 8.0.19-1.el8 mysql80-community
😋
snmp_exporter の generator で Edge Router のメトリクスを取る
これを使う
grafana.com
generator.yml
↑ の generator.yml は古い書き方で現在の generator では使えない。
こうする ↓
modules: edgemax: walk: - ifHCInOctets - ifHCOutOctets - ssCpuIdle - memTotalFree - memTotalReal - hrSystemUptime lookups: - source_indexes: [ifIndex] lookup: 1.3.6.1.2.1.31.1.1.1.1 drop_source_indexes: false
snmp.yml
生成したやつ
# WARNING: This file was auto-generated using snmp_exporter generator, manual changes will be lost. edgemax: walk: - 1.3.6.1.2.1.31.1.1.1.1 - 1.3.6.1.2.1.31.1.1.1.10 - 1.3.6.1.2.1.31.1.1.1.6 get: - 1.3.6.1.2.1.25.1.1.0 - 1.3.6.1.4.1.2021.11.11.0 - 1.3.6.1.4.1.2021.4.11.0 - 1.3.6.1.4.1.2021.4.5.0 metrics: - name: hrSystemUptime oid: 1.3.6.1.2.1.25.1.1 type: gauge help: The amount of time since this host was last initialized - 1.3.6.1.2.1.25.1.1 - name: ifHCOutOctets oid: 1.3.6.1.2.1.31.1.1.1.10 type: counter help: The total number of octets transmitted out of the interface, including framing characters - 1.3.6.1.2.1.31.1.1.1.10 indexes: - labelname: ifIndex type: gauge lookups: - labels: - ifIndex labelname: ifName oid: 1.3.6.1.2.1.31.1.1.1.1 type: DisplayString - name: ifHCInOctets oid: 1.3.6.1.2.1.31.1.1.1.6 type: counter help: The total number of octets received on the interface, including framing characters - 1.3.6.1.2.1.31.1.1.1.6 indexes: - labelname: ifIndex type: gauge lookups: - labels: - ifIndex labelname: ifName oid: 1.3.6.1.2.1.31.1.1.1.1 type: DisplayString - name: ssCpuIdle oid: 1.3.6.1.4.1.2021.11.11 type: gauge help: The percentage of processor time spent idle, calculated over the last minute - 1.3.6.1.4.1.2021.11.11 - name: memTotalFree oid: 1.3.6.1.4.1.2021.4.11 type: gauge help: The total amount of memory free or available for use on this host - 1.3.6.1.4.1.2021.4.11 - name: memTotalReal oid: 1.3.6.1.4.1.2021.4.5 type: gauge help: The total amount of real/physical memory installed on this host. - 1.3.6.1.4.1.2021.4.5 luis@ubuntu ~/snmp_exporter-master/generator $ vi [ruby-2.6.3p62] luis@ubuntu ~/snmp_exporter-master/generator $ cat generator.yml [ruby-2.6.3p62] modules: edgemax: walk: - ifHCInOctets - ifHCOutOctets - ssCpuIdle - memTotalFree - memTotalReal - hrSystemUptime lookups: - source_indexes: [ifIndex] lookup: 1.3.6.1.2.1.31.1.1.1.1 drop_source_indexes: false luis@ubuntu ~/snmp_exporter-master/generator $ cat snmp.yml [ruby-2.6.3p62] # WARNING: This file was auto-generated using snmp_exporter generator, manual changes will be lost. edgemax: walk: - 1.3.6.1.2.1.31.1.1.1.1 - 1.3.6.1.2.1.31.1.1.1.10 - 1.3.6.1.2.1.31.1.1.1.6 get: - 1.3.6.1.2.1.25.1.1.0 - 1.3.6.1.4.1.2021.11.11.0 - 1.3.6.1.4.1.2021.4.11.0 - 1.3.6.1.4.1.2021.4.5.0 metrics: - name: hrSystemUptime oid: 1.3.6.1.2.1.25.1.1 type: gauge help: The amount of time since this host was last initialized - 1.3.6.1.2.1.25.1.1 - name: ifHCOutOctets oid: 1.3.6.1.2.1.31.1.1.1.10 type: counter help: The total number of octets transmitted out of the interface, including framing characters - 1.3.6.1.2.1.31.1.1.1.10 indexes: - labelname: ifIndex type: gauge lookups: - labels: - ifIndex labelname: ifName oid: 1.3.6.1.2.1.31.1.1.1.1 type: DisplayString - name: ifHCInOctets oid: 1.3.6.1.2.1.31.1.1.1.6 type: counter help: The total number of octets received on the interface, including framing characters - 1.3.6.1.2.1.31.1.1.1.6 indexes: - labelname: ifIndex type: gauge lookups: - labels: - ifIndex labelname: ifName oid: 1.3.6.1.2.1.31.1.1.1.1 type: DisplayString - name: ssCpuIdle oid: 1.3.6.1.4.1.2021.11.11 type: gauge help: The percentage of processor time spent idle, calculated over the last minute - 1.3.6.1.4.1.2021.11.11 - name: memTotalFree oid: 1.3.6.1.4.1.2021.4.11 type: gauge help: The total amount of memory free or available for use on this host - 1.3.6.1.4.1.2021.4.11 - name: memTotalReal oid: 1.3.6.1.4.1.2021.4.5 type: gauge help: The total amount of real/physical memory installed on this host. - 1.3.6.1.4.1.2021.4.5
使うモジュールを edgemax へ
- job_name: 'snmp' static_configs: - targets: - 192.168.20.1 metrics_path: /snmp params: module: [edgemax] relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 127.0.0.1:9116
確認

Terrfarom じゃなくても Ansible でもできるよ!S3編
今回は S3 簡単なやつ
使うモジュール
バケットの作成
- name: Create a bucket s3_bucket: name: "{{ project }}-dbbackup" state: present region: ap-northeast-1
ライフサイクルの追加
- name: Add a lifecycle s3_lifecycle: name: "{{ project }}-dbbackup" storage_class: onezone_ia transition_days: 31 state: present status: enabled

なんでみんな Cloudflare を使わないの?無料で使える Cloudflare の機能をご紹介!
よくあるアフィ記事のタイトル風
Cloudflare 無料で色んなことできるのに周りで使っている人が少ないから布教してみる。
- Cloudflare
- Cloudflare の日本でのシェア
- Cloudflare の企業ミッション
- 無料で使ってるときの注意点
- Pro プランでも月額 $20
- Cloudflare はよく落ちるからなぁ、、、
Cloudflare
コンテンツデリバリーネットワークやインターネットセキュリティサービス、分散型ドメイン名サーバシステムを提供するアメリカ合衆国の企業で、閲覧者とホスティングプロバイダー間でリバースプロキシとして動作する。
Cloudflare の日本でのシェア
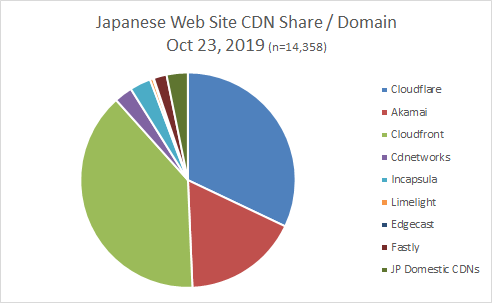
引用元:
tech.jstream.jp
以外に日本でのシェアがあった。
でも Cloudflare を使ってるって声をあまり聞いたことがないので企業で使っているところがあったら教えてください。
Cloudflare の企業ミッション
Cloudflare is on a mission to help build a better Internet.
かっこいい
この企業ミッションを見てから、記事の続きを見てみてください。
無料で使える
大体の必要なことは無料で使える。
(無料)証明書の用意なんてしなくても HTTPS が使える

Cloudflare はクライアントとオリジンサーバーの間に入るリバースプロキシでもある。
例えばデフォルトの Flexible では
ユーザー →(HTTPS) Cloudflare → (HTTP) オリジンサーバー
の振る舞いを行い、何もしなくても HTTPS 接続ができる。
Cloudflare - オリジン間 も HTTPS にすることは可能で
Full or Full(strict) を選べば良い。
Full はオレオレ証明書でも可能だけど、Full(strict) はオリジンサーバー上に信頼された CA が必要になる。
(無料)オリジンサーバーの Public IP が隠せる
リバースプロキシとして作用するので、隠せる。
(無料)Page Rule によって痒いとこに手が届く

例えば、f.easyuploader.app/*/upload/* のリクエストパスに対しておもむろにキャッシュを効かせられる。
無料ユーザーなら3つまで Page Rule が作成可能で、アカウント単位ではなくドメイン単位なので優しい。
(無料) Access 機能はまじですごい
特定のサブドメイン、または特定のパスに対してアクセス制限をかけたい場合、Cloudflare Access なら無料でできる。

まずはプロバイダーを選択する。
ここでは Google を選択。

次に、管理しやすいようにグループを作成する。
メール認証でも、完全一致ではなく特定のドメインの人でもできるのでご安心を。

これは ドメイン/wordprpess/wp-admin/ に対して、Google 認証でアクセス制限をかけてる。

実際にアクセスをすると、Google のログイン画面が出てくる。
先程のグループ email の中で設定した Google アカウントの人のみアクセスできるようになる。
仕組みとしてはログインするとポリシーを作成したときの Session Duration が有効期限の JWT が送られてくる。

管理ツールとかも、この Access に入れればログイン機能実装しなくても使えちゃう。
中身 JWT だし。すごいよ Cloudflare Access。しかも無料で多分これは無制限に作れる。
これに加えて例えばバッチでこの Access 配下のリソースに触りたい時、特定の IP からは bypass するという機能も無料で使える。
(無料)Rate Limit によるブルートフォースの対策もできちゃう

この例では *.easyuploader.app に対して 1パブリックIP から1分間に50回のリクエストがあった場合に
1時間その IP をブロックするできる。
無料では1つしか作成できないけど、これもドメイン単位。すごい。
(有料)Global Load Balancer もある
月額 $5 で Global Load Balancer が使える。
一時期使ってたけど今は使ってないので画像つきで紹介はできないんですが、普通に LB です。
ファイアウォールイベントで不正なアクセスを確認できる




キャッシュのパージは3秒で消える
uploader.xzy.pw
個人サービスでいくつか削除依頼でファイルを削除したりするけど、Cloudflare 上でキャッシュをパージすると3秒ぐらいでアクセスできなくなる。パージも速い。
SDK からもできるよ
func deleteCacheFromCF(fileName string) error { pcr := cloudflare.PurgeCacheRequest{ Files: []string{ fmt.Sprintf("https://f.easyuploader.app/%s/upload/%s", config.MinioBucket, fileName), }, } _, err := cf.API.PurgeCache(cf.ID, pcr) return err }
AWS のリソースとも組み合わせられる
一時期 S3 を使っていたときに、Cloudflare と組み合わせて使っていた。
s3+ CloudFront が定番だけど、s3 + Cloudflare も良い。無料だよ!
Lambda@Edge 的な Cloudflare Workers
Workers が Cloudflare のエッジで実行されるコンピューティングで
Workers KV が Cloudflare のネットワーク内にある KVS。
blog.luispc.com
でも正直使いみちは分からない。遅いし、、、。
無料で使ってるときの注意点
今まで Cloudflare を使ってきて2つ困ったことがあった。
client maximum upload size
最大で 100MB
Pro でも 100MB
Business で 200MB
Enterprise で 500+ MB
クライアントから 100MB 以上のファイルを送ってもらうには色々注意が必要。
一昔までクライアントからチャンクしてバックエンドで細かく保存して最後に1つにして、アップロードするっていう仕組みを作ったけどそれはやめて、Cloudflare を通さずに直接 minio に送るようにした。(署名付きURL)
Cloudflare はよく落ちるからなぁ、、、
去年は2回大きな障害があった記憶がある。
1個は Version のミス、もう1個は Cloudflare のミス。
スマートルーティングと階層型キャッシングを通じたパフォーマンス | Cloudflare
そりゃ Cloudflare が落ちたら Cloudflare は不安定という印象が付く。
でも、他の CDN だって落ちてる。
社内で某 CDN のことで良くない噂も聞いたりする。
Cloudflare は不安定だから っていう理由で Cloudflare を選択肢から外すのは悲しい;;
僕も別に Cloudflare について熟知しているわけじゃないけど、CDN を選択する際にぜひ候補として考えてほしいです。
ここでは Cloudflare 全体の 3.5割ぐらいのことしか説明できませんでしたが無料なので1度触ってみてください。